Quality Assurance
Quality assurance is a key component of every coding project, no matter how small. We need to be confident that our code works as intended, and that any software we provide to clients or other users reliably meets their needs. Since programming is by nature open-ended, there is no one-size-fits-all solution to ensure quality code, however, many tools exist to help achieve this goal. This section presents a high-level discussion of coding errors, then introduces four tools for preventing, finding, and fixing errors: testing, debugging, test-driven development, and code review, and wraps up with some general recommendations for ensuring quality on different types of coding projects.
Errors
During development, no matter how careful you are and how well you follow best practices, you're going to run into errors. Errors (also known as bugs) come in all shapes and sizes, from simple syntax errors like a missing semicolon to more complicated issues like memory leaks. For now, let's simplify and consider two general categories of errors: fatal errors that cause execution of your code to stop, and non-fatal errors that allow your code to continue executing.
Fatal Errors
Fatal errors occur when a computer is forced to stop executing code because it doesn't know how to proceed. This can happen for many reasons; some common examples follow:
- A syntax error, which can be as simple as improper indentation or a missing parenthesis, causes the computer to not be able to interpret the code.
- The computer can't find an object because it doesn't exist or isn't in the correct location.
- An operation requires an argument of a specific type, but the argument passed to it has a different type.
- An arithmetic operation fails to return a result (e.g., a value is divided by zero).
The good news is that when these errors occur, it's impossible to miss them. An error message will be returned, typically with information on what part of the code caused execution to fail. The bad news is that the real problem may not actually be in the line of code that directly caused the failure. For example, the root cause of a divide by zero error may not actually be in the line of code where the division takes place, but instead be in some code executed earlier that erroneously assigned a zero value to the divisor. Debugging (discussed below) is essential to pinpointing the true cause of errors like this.
TIP
When you encounter a fatal error, read the error message carefully. They can often be confusing when you're first starting to code, but the ability to effectively interpret error messages is an important skill. Even if you have some intuition about the likely cause of the error, take a look at the error message before jumping right into editing the code. This can save you time chasing an error that's not where you think it is.
Finally, keep in mind that over the course of development, you won't actually run every piece of your code in every possible context, so there may be fatal errors lurking that you just haven't encountered. Comprehensive testing (described below) can help you identify many of these errors.
TIP
A modern development environment like VS Code or RStudio with a linter configured will automatically help you find and prevent errors as you write code. This is mostly relevant for syntax errors, but some other errors can be automatically detected too.
Error Handling
In many cases, you may want to handle certain types of errors that ordinarily would be fatal and allow code to continue executing. Consider the following two examples:
- You've written a command-line utility that prompts the user to type in the name of an input file. If you haven't incorporated error handling, when a user enters the name of a file that doesn't exist, the program would crash and return an error message that likely wouldn't be meaningful to the user (as an aside, it's tempting to blame this on the user, but the responsibility is on you as a programmer to deal with user error gracefully). Instead, it would be much better if the program told the user "Sorry, [filename] cannot be found. Please try again." or something similar, and gave them another chance.
- You're writing code that returns coordinates for a set of input addresses (don't actually do this, because there are plenty of geocoding packages out there!). Your code loops through an set of addresses and calls a geocoding function on each. Without incorporating error handling, if your geocoding function fails for a single address, your code will stop executing. Especially since address data can be quirky, it would be a big improvement if, when geocoding failed for a single address, execution moved to the next address, leaving empty values (or some other placeholder) for the coordinates of the failed address. It might also be a good idea to print a message telling the user "Unable to locate [address]." or similar.
While syntax varies by language, the type of error handling described above can typically be accomplished using try...catch logic ("try...except" in Python). Try...catch logic tries to execute a piece of code, and if an error occurs, it catches the error and executes another piece of code. The code that is executed when the error is caught can, and in most cases should, depend on the type of error encountered. As suggested in the geocoding example above, when handling errors, it is often a good idea to print error messages to the console and/or a separate log file. The following example illustrates an implementation of try...catch logic for the geocoding example above.
# assume geocode(address) is provided by an external package
def geocode_multiple(address_list):
coords = []
for address in address_list:
try:
coords.append(geocode(address))
except AddressNotFoundError:
print(f'Address not found: {address}')
coords.append('no coords')
return coords
# assume geocode(address) is provided by an external package
geocode_if_found <- function(address) {
tryCatch(
return(geocode(address)),
error = function(e) {
if (e$message == paste("Address not found:", address)) {
print(e$message)
return("no coords")
} else {
stop(e$message)
}
}
)
}
# would be used with lapply to geocode a vector of addresses:
# lapply(address_vector, geocode_if_found)
// assume geocode(address) is provided by an external package
function geocodeMultiple(address_list) {
var coords = [];
address_list.forEach((address) => {
try {
coords.push(geocode(address));
} catch (error) {
if (error instanceof AddressNotFoundError) {
console.log(`Address not found: ${address}`);
coords.push("no coords");
} else {
throw error;
}
}
});
return coords;
}
In the example, when the geocode function returns an Address Not Found Error, an error message is printed to the console, "no coords" is written to the output in place of the missing coordinates, and the geocoding process continues with the next address. If any other fatal error is encountered, execution will stop just as it would without the try...catch logic. Note that the structure of the R example is different than the Python and JavaScript examples. Since looping over vectors is generally discouraged in R, the try...catch logic is implemented in a geocode_if_found function that wraps the external geocode function and adds the error handling logic. This would then be used with lapply to geocode a vector of addresses. Similar logic could be implemented using map functions in Python and JavaScript instead of for-loops if desired.
WARNING
Be sure to limit this type of error handling to specific error types in specific contexts, so you can be certain you're providing the appropriate response to the exact situation you want to address. Generic try...catch blocks aimed at letting the code continue to run in order to get around an unknown error can be dangerous.
Non-Fatal Errors
Non-fatal errors typically occur when the logic in your code isn't what you intended, and despite the description, these can often be more dangerous than fatal errors. For example, you might have forgotten to convert from daily to annual trips, or multiplied by a factor instead of dividing. In these cases, nothing will prevent the code from executing, but erroneous outputs will be produced. Since the code executes without any trouble, there is also no indication that your code isn't working as expected, so you likely won't discover there is an issue until you examine the outputs. If your code is sufficiently complex, this can also make it difficult to pinpoint the exact location of the issue, since it could be at any point in the code. Of course if there are multiple non-fatal errors, the process of finding them becomes even more difficult. As with fatal errors, testing and debugging are both helpful in pinpointing, fixing, and preventing non-fatal errors.
Testing
In software development, testing is the process by which software is checked for errors and to ensure it meets its specification. The testing process varies greatly by project, and can involve a variety of types of tests and testing techniques. Several of the most important types of testing are introduced below.
- Unit testing focuses on testing the smallest units of code, such as single functions, to make sure they work as intended.
- Integration testing focuses on the integration of modules to make sure they work together as intended.
- Regression testing focuses on making sure working code continues to work properly as changes are made elsewhere in the code.
- User acceptance testing focuses on making sure the software meets the end user's requirements.
Development of any software intended for an external user should formally incorporate each of these types of tests (and possibly others). On the other hand, small internal utilities or data analysis scripts can typically get by with only informal versions of a few of these.
The testing process typically involves a combination of manual and automatic tests. Both types are described below.
Manual Testing
Whether you realize it or not, you're probably already doing quite a bit of manual testing of your code. Manual testing occurs when you're running pieces of your code (or the whole thing) to make sure everything is working as intended, that no fatal errors are occurring, etc. This type of testing is useful because it is quick and flexible, but has the drawbacks of being ephemeral and non-systematic.
While unit and integration testing can to a large extent be covered by automated testing (described below), manual testing is the only way to find issues related to usability and design, so be sure to spend some time performing manual tests targeting these areas. Since user acceptance testing involves delivering the application to users and getting feedback, it is also a primarily manual process.
As with most technical work at Steer, checks to make sure that various inputs, outputs, and intermediate calculations make sense are essential, and these sense-checks are difficult to automate since they generally rely on human judgment. Where possible, it is useful to incorporate benchmarks into your sense-checking. For example, if your code includes a step that calculates trip rates, you may want to compare the trip rates with trip rate data from another source to see if the values are broadly similar.
Automated Testing
Automated testing involves writing tests (typically unit and integration tests) in code, and running these tests frequently during the development process.
Automated unit and integration tests are generally based on the concept of "assertions"—typically a test will call a specific function with a certain set of inputs, and assert that the output should meet a certain condition. If the condition is true, the test has passed; if the condition is false (or if there's a fatal error before the assert statement), the test has failed.
While numerous testing frameworks enable you to write these types of tests; the following are recommended:
As an example, you might write a function to calculate the area of a triangle from the lengths of its sides. Your first test might assert that your function returns a value of 6 when given inputs of 3, 4, and 5. However, just because this test passes doesn't mean you're in the clear. Your function may work for scalene right triangles, but you'll also need to test that it works for triangles of various other types. This is where you want to think about edge cases and try to cover as much ground as possible. Also, you'll want to make sure you not only test that the function works for any valid triangle (the "happy path"), but you'll also want to test that the function returns an appropriate error when given side lengths that can't form a valid triangle (the "sad path"). Below are some sample tests for this example.
import math
import pytest
def test_scalene_right():
assert area_from_triangle_sides(3, 4, 5) == 6
def test_scalene_nonright():
assert math.isclose(area_from_triangle_sides(2, 6, 7),
5.562, abs_tol=0.001)
def test_equilateral():
assert math.isclose(area_from_triangle_sides(2, 2, 2),
1.732, abs_tol=0.001)
def test_isoceles():
assert math.isclose(area_from_triangle_sides(0.5, 0.5, 0.2),
0.049, abs_tol=0.001)
def test_negative_side_length():
with pytest.raises(
InvalidTriangleError,
match='all side lengths must be greater than zero'
):
area_from_triangle_sides(-3, 4, 5)
def test_incompatible_side_lengths():
with pytest.raises(
InvalidTriangleError,
match='c must be less than a plus b'
):
area_from_triangle_sides(1, 1, 3)
library(testthat)
# test scalene right
expect_equal(area_from_triangle_sides(3, 4, 5), 6)
# test scalene non-right
expect_equal(area_from_triangle_sides(2, 6, 7),
5.562, tolerance = 0.001)
# test equilateral
expect_equal(area_from_triangle_sides(2, 2, 2),
1.732, tolerance = 0.001)
# test isoceles
expect_equal(area_from_triangle_sides(0.5, 0.5, 0.2),
0.049, tolerance = 0.001)
# test failure due to negative side length
expect_error(
area_from_triangle_sides(-3, 4, 5),
"InvalidTriangleError: all side lengths must be greater than zero"
)
# test failure due to incompatible side lengths
expect_error(
area_from_triangle_sides(1, 1, 3),
"InvalidTriangleError: c must be less than a plus b"
)
test("handles scalene right triangle", () => {
expect(areaFromTriangleSides(3, 4, 5)).toBe(6);
});
test("handles scalene non-right triangle", () => {
expect(areaFromTriangleSides(2, 6, 7)).toBeCloseTo(5.562);
});
test("handles equilateral triangle", () => {
expect(areaFromTriangleSides(2, 2, 2)).toBeCloseTo(1.732);
});
test("handles isoceles triangle", () => {
expect(areaFromTriangleSides(0.5, 0.5, 0.2)).toBeCloseTo(0.049);
});
test("raises error for negative side length", () => {
expect(() => areaFromTriangleSides(-3, 4, 5)).toThrow(InvalidTriangleError);
expect(() => areaFromTriangleSides(-3, 4, 5)).toThrow(
"all side lengths must be greater than zero"
);
});
test("raises error for incompatible side lengths", () => {
expect(() => areaFromTriangleSides(1, 1, 3)).toThrow(InvalidTriangleError);
expect(() => areaFromTriangleSides(1, 1, 3)).toThrow(
"c must be less than a plus b"
);
});
Generally, the best approach is to start with unit tests and build up to integration tests, so you're starting with the smallest units of code and moving toward larger ones. Keeping tests in place as you add to the set also provides a "harness" to protect against regression. This way, if you add something new to your code that causes a test that was previously passing to fail, you'll know right away that there's a regression issue you need to address.
In anything beyond a very basic standalone script, tests should typically be separated from the program logic and placed in their own separate module(s). This helps to keep your code better organized, and makes it easier for some testing frameworks to automatically locate your tests.
The appropriate level of automated testing will depend on the project and its context. A mission-critical application may warrant a full test-driven development approach (see below) with strong test coverage in every module, while a relatively simple data analysis script may only need a few tests. In the latter case, you should at least build in some automatic checks at key points in your code. The open-ended nature of coding makes it impossible to specify exactly what tests to include, but the following are a few suggestions:
- check that row counts match expected values after data frames are merged.
- check that totals match expected values after aggregation over groups.
- check that minimum and/or maximum values of key data items are within reasonable ranges after important computations.
When used effectively, automated tests can help you find errors before they become major problems and ensure future updates don't break code that was previously working. Just keep in mind that automated testing is only as good as the coverage of the tests you write, so you can't rely on it to catch every error.
Debugging
Debugging is the process of pinpointing and fixing errors that arise. In the past, this typically involved adding print statements at key points in code and rerunning to check variable values, which could be extremely tedious. Fortunately, modern development environments include debugging tools that greatly simplify the debugging process, but it can still be slow and painful.
After minimal configuration, modern IDEs typically allow you to run code in some kind of debug mode. When an error or a user-specified breakpoint is encountered, execution pauses and an interactive debugging process is triggered. While actively debugging, the user typically can step through/into/over pieces of code and can view the values of variables or other user-defined expressions at any point.
In web development, server-side code is typically debugged in an IDE as described above. Since client-side code runs in the end user's web browser, all modern web browsers include JavaScript consoles and debugging tools that can typically be accessed via a "Developer" menu (or similar). The in-browser debugging tools function similarly to those included in IDEs and also provide the added ability to examine the active web page at any point.
TIP
In-browser developer tools also enable you to test how your web application will look and function on mobile and other devices with various screen sizes and input types. This is essential for modern web development, as all sites need to be responsive to a wide range of client interfaces.
Once you have a good handle on the debugging features of your development environment, you'll have a powerful set of tools at your disposal, but the actual process of pinpointing and eliminating bugs remains largely manual. When a bug pops up, you'll need to use debugging tools along with your knowledge of the code and information you glean from error messages and interactive debugging to follow leads until you find the root problem and figure out how to solve it.
"Debugging is like being the detective in a crime movie where you are also the murderer."
— Filipe Fortes
While debugging is much easier than it used to be, it's still a time-consuming process that takes practice to get comfortable with. Ideally though, you'll be able to proactively prevent most errors before they happen, thereby minimizing the time you spend debugging. This is where test-driven development (described below) can help.
Test-Driven Development
Test-driven development (TDD) is a process aimed at proactively preventing errors by writing unit tests before you actually write your code (yes, you read that correctly!).
The process, which is illustrated in the figure below, is based on a cycle of Red-Green-Refactor that is repeated for each unit of code (e.g., a single function). Each step in the cycle is described below:
- The developer writes a set of tests for the particular unit, being careful to take into account various possible contexts, edge cases, and happy and sad paths as described above under Automated Testing. At this point, the code to actually implement the unit has not been written yet, so the tests fail and are said to be red.
- The developer writes just enough code that the tests written in Step 1 are now passing, and said to be green. To this point, readability, efficiency, and other best practices are not high priorities.
- The developer revises the code to make improvements of various types, including those aimed at improving readability and efficiency, and following other best practices, while making sure the tests still pass. This process of revision without changing the code's overall behavior is called refactoring, and is described in greater detail in the next section of this guide.
The test-driven development cycle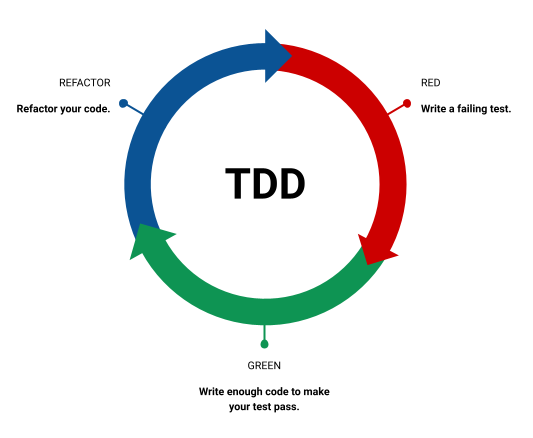
This process essentially puts guardrails and a feedback system in place before any coding begins, which allows you to focus on the target one manageable chunk of code at a time, while constantly receiving feedback (via failed tests) that helps you know where adjustments need to be made. TDD requires significant upfront investment in the form of time required to write tests before coding, but generally pays off in the long run in time saved debugging.
As with many of the quality assurance tools described in this guide, your mileage with TDD will vary depending on the type and size of project you're working on. If you're working on any type of software development project, incorporating TDD is highly recommended. While TDD is generally geared toward software development, its concepts can still be useful in data science and other contexts, and may be worth incorporating to a lesser extent.
TIP
If you're thinking the claim above that TDD "proactively prevents errors" stretches the truth a bit, you wouldn't be entirely wrong. Technically, failed tests correspond to errors, and TDD involves many, many failed tests. The key point, however, is that, rather than debugging, which focuses on finding and fixing errors after they're discovered and requires a great deal of mental energy, TDD allows the coder to focus on the much more positive and less taxing task of writing code that passes the tests.
Code Review
Code review involves a coder who is familiar with the language(s) and packages being used—but not involved in writing the code—reviewing the code and providing feedback. The reviewer should typically be someone with a greater amount of relevant coding experience than the original programmer, but in some cases it may make sense for someone with a similar level of experience to review the original programmer's code. It is also useful if the reviewer is able to run the code as they are reviewing, since this makes it easier to more fully understand how the code works. Code review is useful for feedback on all aspects of code, from whether there might be edge cases the code doesn't cover, to the presence of user interface issues, to whether the code's style follows best practices.
Recommendations
As mentioned above, the appropriate set of quality assurance tools to use depends on the type and complexity of each individual coding project.
For a standalone data analysis script, identify key potential failure points and write some automated tests focused on these, using test-driven development as appropriate. Be sure to do plenty of sense-checking and other manual testing, and ask someone to review your code once it's completed.
For a software development project, whether a small web application, an R package, or a large Python-based travel model, develop a quality assurance plan early on in the process. Incorporate test-driven development as a core component of your plan and supplement it with manual testing as necessary. Conduct code reviews as individual project components are completed, and if your project requires user acceptance testing, be sure you budget sufficient time for iteration based on tester feedback.